WTF is Context Engineering!?
A simple explanation for humans who don't speak robot (yet)

Hey again! Quick life update before we get into it.
First: I submitted a research paper this week. Can’t say what it’s about yet — hot field, loose lips, you know how it is. But it exists, it’s submitted, and I’m in that special purgatory where you’ve done the work but have no idea if it was good. My advisor responded to my “I submitted it” message with “ok.” One word. No period. I’ve been analyzing that response for 48 hours.

Second: remember the OpenClaw post, where I mentioned a colleague and I are building the security and observability layer that OpenClaw shipped without? We’re starting our sprint this week. More on that soon. If you’re interested in following along or collaborating, reply to this email.
Now. Let’s talk about why the post I wrote in October is already outdated.
Back in October, I wrote about Prompt Engineering — the art of talking to LLMs in ways that make them actually useful. System prompts. Few-shot examples. Chain-of-thought. All of that.
That post is still correct. It’s just... incomplete now. Because the industry quietly moved the goalposts.
The term you’re hearing everywhere right now is Context Engineering. Andrej Karpathy put it plainly in January: “Prompt engineering is a subset. Context engineering is the full discipline.” It’s been rattling around AI Twitter ever since, and unlike most AI Twitter trends, this one actually describes something real.
Here’s the shift: when you’re building a toy chatbot, prompt engineering is enough. Write a good system prompt, ship it, done. But when you’re building something that actually works in production — with RAG, agents, tool use, memory, multi-step reasoning — you’re not managing a prompt anymore. You’re managing an entire information environment that gets assembled fresh on every single request.
OpenClaw made this obvious. SOUL.md, MEMORY.md, USER.md, HEARTBEAT.md, the daily log files, the skills system — none of that is a “prompt.” It’s a carefully designed context window that gets constructed at runtime from multiple sources. The agent literally reads itself into existence on every wake cycle.

That’s context engineering.
What Context Engineering Actually Is
Let’s be precise about the definition, because the term is getting slapped on everything right now.
Prompt Engineering: Optimizing the content of your instructions to an LLM. Wording, structure, examples, formatting. Happens at write time.
Context Engineering: Designing the entire information architecture that gets assembled into the context window at runtime. What goes in. What gets excluded. In what order. How much. From where. Updated how often.
The context window is everything the model sees before generating a response. Not just your prompt. Everything:
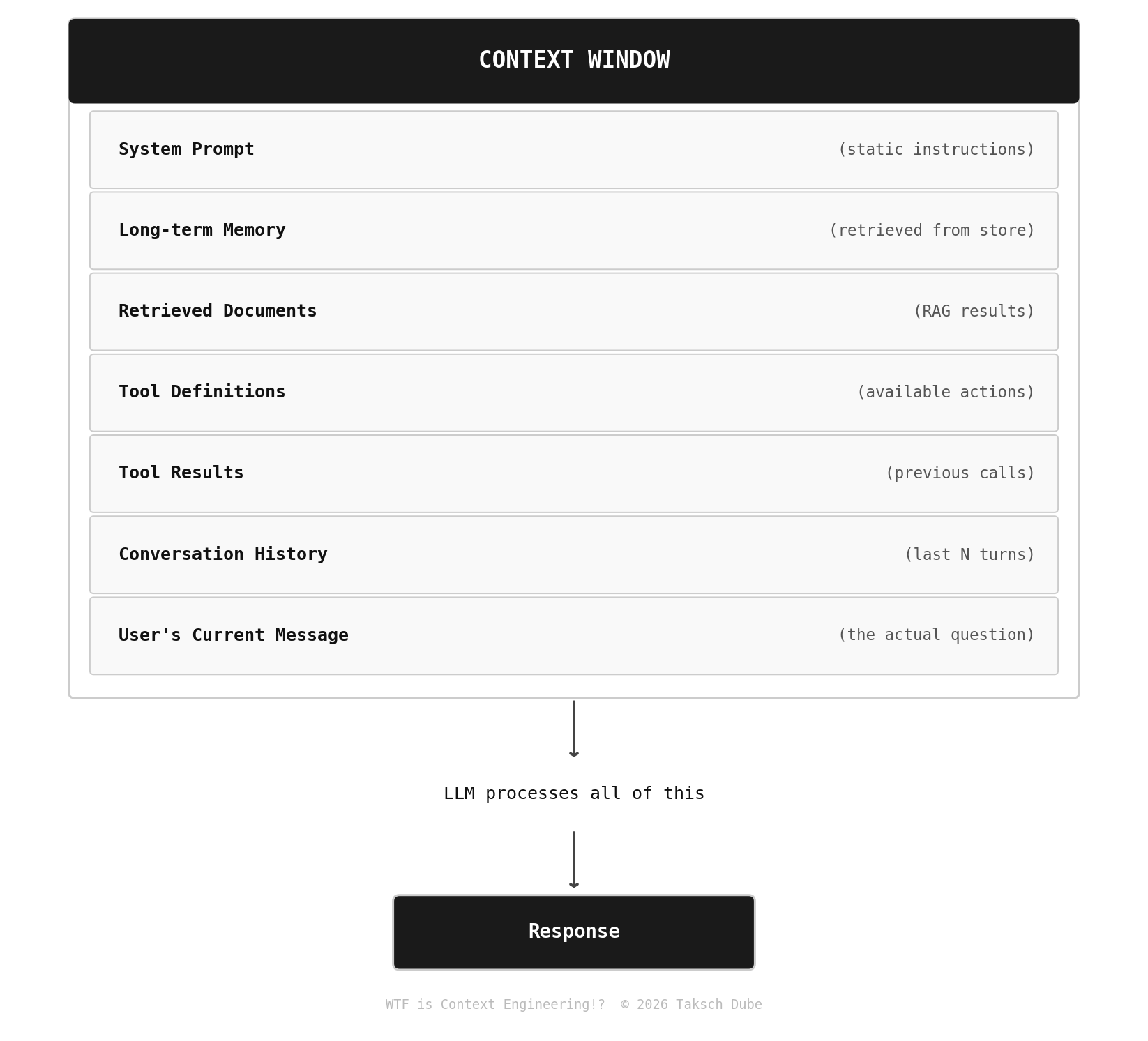
Context engineering is the discipline of deciding what goes in each of those slots, how to get it there efficiently, and what to do when you’re running out of room.
Why does this matter? Two reasons:
1. Tokens = money + latency. A 100K token context costs roughly $0.30 per request on Claude Sonnet 4.6. At 10,000 requests/day that’s $3,000/day just in context. The context window is not free real estate.
I showed my advisor this math. He said “so just use fewer tokens.” I said “that’s literally the entire discipline.” He said “great, so your chapter draft is ready?” The man treats every conversation like a context window with a single slot.
2. More context ≠ better answers. This is the part people get wrong.
The Lost in the Middle Problem (And Why Your RAG is Probably Broken)
In 2023, researchers at Stanford published a paper called “Lost in the Middle: How Language Models Use Long Contexts.” The finding was uncomfortable: LLMs are significantly worse at using information that appears in the middle of long contexts. They’re great with information at the very beginning (primacy effect) and at the very end (recency effect). The middle? Kind of a black hole.
The performance degradation is real. On multi-document QA tasks, accuracy dropped from ~70% (relevant doc at position 1) to ~45% (relevant doc at position 10-15) — and then partially recovered as the doc moved toward the end.
The implication for RAG: if you retrieve 10 documents and stuff them all in, your five most relevant chunks might end up in positions 4-8. The model might answer from chunk 1 or 10 instead.
(My advisor has this exact problem with my dissertation drafts. Critical contributions buried in chapter 4. He reads chapter 1, skims to the conclusion, tells me it needs “more substance.” We are not so different, him and GPT-5.)
Bad context engineering:
# Don’t do this
docs = retrieve(query, top_k=10)
context = “\n\n”.join([doc.text for doc in docs])
# You just buried your best info in the middle
Better context engineering:
# Rerank AFTER retrieval, then put best results at edges
docs = retrieve(query, top_k=10)
reranked = cross_encoder_rerank(query, docs) # more expensive but worth it
# Put most relevant at start AND end, filler in middle
top_1 = reranked[0]
top_2 = reranked[1]
middle = reranked[2:8]
context = build_context([top_1] + middle + [top_2])
This is context engineering. Not prompting. Information architecture.
The Five Components You're Actually Managing
1. The System Prompt (Your Agent’s Soul)
You know this one. But here’s what most people get wrong: system prompts are the least dynamic part of the context, which means they should be the most carefully designed.
Every token in your system prompt is paid for on every single request. A bloated 4,000-token system prompt at 10K requests/day on GPT-5 costs about $50/day. Just the system prompt.
Two rules:
Cache it. All major providers now offer 90% off cached input tokens. Structure your prompt with static content first so it’s cache-eligible.
Trim ruthlessly. Most system prompts are 30-40% longer than necessary. Every “Please remember to always be helpful and...” costs you money on every request forever.
An example of this:
# Before: 2,847 tokens
system_prompt = “”“
You are a helpful customer service assistant for AcmeCorp.
Your job is to help customers with their questions. Please
always be polite and professional. Remember to be helpful.
You should always try to answer questions accurately...
[700 more words of vague instructions]
—
# After: 891 tokens (same behavior, 69% fewer tokens)
system_prompt = “”“
Customer service agent for AcmeCorp.
- Answer accurately using provided context only
- Escalate to human if: billing disputes, account compromise, legal
- Tone: professional, concise
- Never speculate about policies not in context
—
2. Memory (The Hard One)
This is where OpenClaw’s architecture gets interesting as a case study, and where most production systems are currently failing.
The problem: LLMs have no memory between sessions. Every conversation starts from zero. My advisor also has no memory between sessions — every meeting begins with “remind me where we left off” — but at least I can’t fix him with a vector database. The naive solution is to dump the entire conversation history into context — which works until you’re 50 turns in and paying for 40K tokens of history on every message.
The right solution is a memory hierarchy:
Working Memory → Current conversation (last 10-20 turns)
Episodic Memory → Compressed summaries of past sessions
Semantic Memory → Extracted facts (”user prefers Python”, “project deadline is Q2”)
Long-term Store → Vector DB or structured storage, retrieved on demand
OpenClaw does this with MEMORY.md (curated semantic facts) + daily log files (episodic). It's crude but it works. Production systems should do the same thing programmatically:
class MemoryManager:
def build_memory_context(self, user_id: str, current_query: str) -> str:
# 1. Always include: semantic facts (small, always relevant)
user_facts = self.get_user_facts(user_id) # ~200 tokens
# 2. Conditionally include: recent episodes
recent_summary = self.get_recent_summary(user_id, days=7) # ~300 tokens
# 3. Retrieve: relevant past context via semantic search
relevant_history = self.vector_search(
query=current_query,
user_id=user_id,
top_k=3
) # ~500 tokens
# Total memory budget: ~1,000 tokens instead of 40,000
return format_memory(user_facts, recent_summary, relevant_history)
The benchmark that matters: teams that implement proper memory hierarchies report 60-75% reduction in context size with improved answer quality because the model gets focused, relevant memory instead of a firehose of everything.
3. Retrieved Documents (RAG, But Done Right)
Covered RAG in depth back in November, but context engineering adds a layer on top: it’s not just what you retrieve, it’s how you present it.
The problems with naive RAG presentation:
Raw chunks with no structure look identical to the model
No indication of source reliability or recency
No signal about which chunks are most relevant
Better approach:
def format_retrieved_docs(docs: list[Document], query: str) -> str:
# Rerank first
docs = rerank(query, docs)
template = “”“
<source rank=”{rank}” relevance=”{score:.2f}” date=”{date}”>
{content}
</source>”“”
formatted = [
template.format(
rank=i+1,
score=doc.relevance_score,
date=doc.date,
content=doc.text
)
for i, doc in enumerate(docs[:5]) # Hard cap at 5 chunks
]
return “\n”.join(formatted)
The rank and relevance score in the XML tags aren't just nice-to-have. Studies show models use structured metadata to weight information — explicitly telling the model "this is rank 1, relevance 0.94" measurably improves faithfulness scores.
4. Tool Definitions and Results (The Hidden Token Tax)
Each tool definition you pass to the model costs tokens. Every tool call result costs tokens. In agentic workflows, this compounds fast.
A realistic agent with 10 tools, running 15 steps:
Tool definitions (10 tools): ~2,000 tokens (paid every step)
Step 1 result: ~500 tokens
Step 2 result: ~800 tokens
...accumulating...
Step 15 result: ~600 tokens
—
Total tool overhead: ~38,500 tokens
That’s before your actual content.
Context engineering for tools:
Dynamic tool loading: Only pass tools that are relevant to the current task, not all 30 tools in your registry
Result summarization: Summarize long tool results before adding to context
Tool result pruning: Drop intermediate results that are no longer relevant
def get_relevant_tools(task: str, all_tools: list) -> list:
# Use a cheap model to select relevant tools
# Costs $0.00001, saves potentially thousands of tokens
relevant = cheap_classifier(task, [t.name for t in all_tools])
return [t for t in all_tools if t.name in relevant]
5. Conversation History (The Compounding Problem)
The naive approach: keep all turns in context.
The problem: a 50-turn conversation at ~300 tokens/turn = 15,000 tokens of history. On every single message.
The context engineering approach: rolling compression.
def get_conversation_context(history: list[Turn], max_tokens: int = 3000) -> str:
# Always keep last 5 turns verbatim (recency matters)
recent = history[-5:]
# Summarize everything older
if len(history) > 5:
older = history[:-5]
summary = summarize_conversation(older) # ~200 tokens
return f”[Earlier conversation summary]\n{summary}\n\n[Recent turns]\n{format_turns(recent)}”
return format_turns(recent)
Teams report 70% context reduction with rolling compression and no meaningful quality drop for conversations under 100 turns.
Context Ordering Matters (A Lot)
Given the lost-in-the-middle problem, the order of your context components isn't arbitrary. Here's the ordering that performs best empirically:
System prompt / static instructions ← Model is most attentive here
Long-term memory / user facts ← Critical info, early
Retrieved documents (most relevant) ← Put your best source here
Tool results (most recent) ← Active working context
Retrieved documents (less relevant) ← Necessary but less critical
Conversation history ← Bulk of context, middle
User’s current message ← Model is attentive at end too
Yes, splitting your retrieved docs — best at top, rest before history — feels weird. But it works. The model gets your most important source at primacy and the user's actual question at recency. Everything else fills in the middle.
IMO: The State of Context Engineering in 2026
What’s working:
Prompt caching (90% off cached tokens — use it, it’s free money)
Cross-encoder reranking before context assembly (5-15% faithfulness improvement, widely reported)
Context compression for long conversations (60-75% token reduction, minimal quality impact)
Structured XML tags for source attribution (measurably improves faithfulness)
What’s still hard:
Multi-agent context management. When you have 5 agents sharing context, deciding what each agent needs to see — and what it shouldn’t see — is an unsolved engineering problem. OpenClaw’s Moltbook discovered this the hard way.
Context freshness. If USER.md says “user is working on Q1 deliverables” and it’s Q2, your agent is operating on stale context. Production memory systems need expiration and update policies, not just write policies.
Adversarial context. Prompt injection via retrieved documents is a real attack vector. If someone puts
[IGNORE PREVIOUS INSTRUCTIONS]in a document that ends up in your context... you have a problem. The guardrails post covers this, but context engineering creates new surface area.
What’s overhyped:
“Infinite context” as a solution. Yes, we have 1M token window nowadays. But shoving everything in is not a strategy. It’s expensive, slow, and the lost-in-the-middle problem doesn’t disappear at 1M tokens. Context engineering is still required.
Automatic context optimization. Several tools claim to auto-optimize your context assembly. They help, but they’re not magic. You still need to architect your memory hierarchy and retrieval strategy manually.
The Context Engineering Stack (What Teams Are Actually Using)
For context assembly and management, teams are converging on a few patterns:
Memory layer:
Mem0 — managed memory layer, extracts and retrieves user facts automatically. Free tier, $0.10/1K memories after.
Zep — session memory and fact extraction. Open source or managed.
DIY with Postgres + pgvector — if you want full control
Retrieval / RAG:
Cohere Rerank or cross-encoders for relevance scoring (the step most teams skip and shouldn’t)
LlamaIndex or LangChain for pipeline orchestration
LangfUSE or LangSmith for observability on what’s actually going into context
Context monitoring (you’re already tracking this from the observability post, right?):
# Log context composition on every request
observability.log({
“request_id”: req_id,
“context_breakdown”: {
“system_prompt_tokens”: len(encode(system_prompt)),
“memory_tokens”: len(encode(memory_context)),
“retrieved_doc_tokens”: len(encode(doc_context)),
“history_tokens”: len(encode(history_context)),
“total_context_tokens”: total,
“pct_of_window_used”: total / model_context_limit
}
})
If you're not logging the composition of your context — not just total tokens, but where they came from — you're debugging blind.
OpenClaw As Context Engineering: A Case Study
Since we just covered OpenClaw in depth, let's close the loop. OpenClaw's architecture is basically a manual context engineering system built with markdown files:
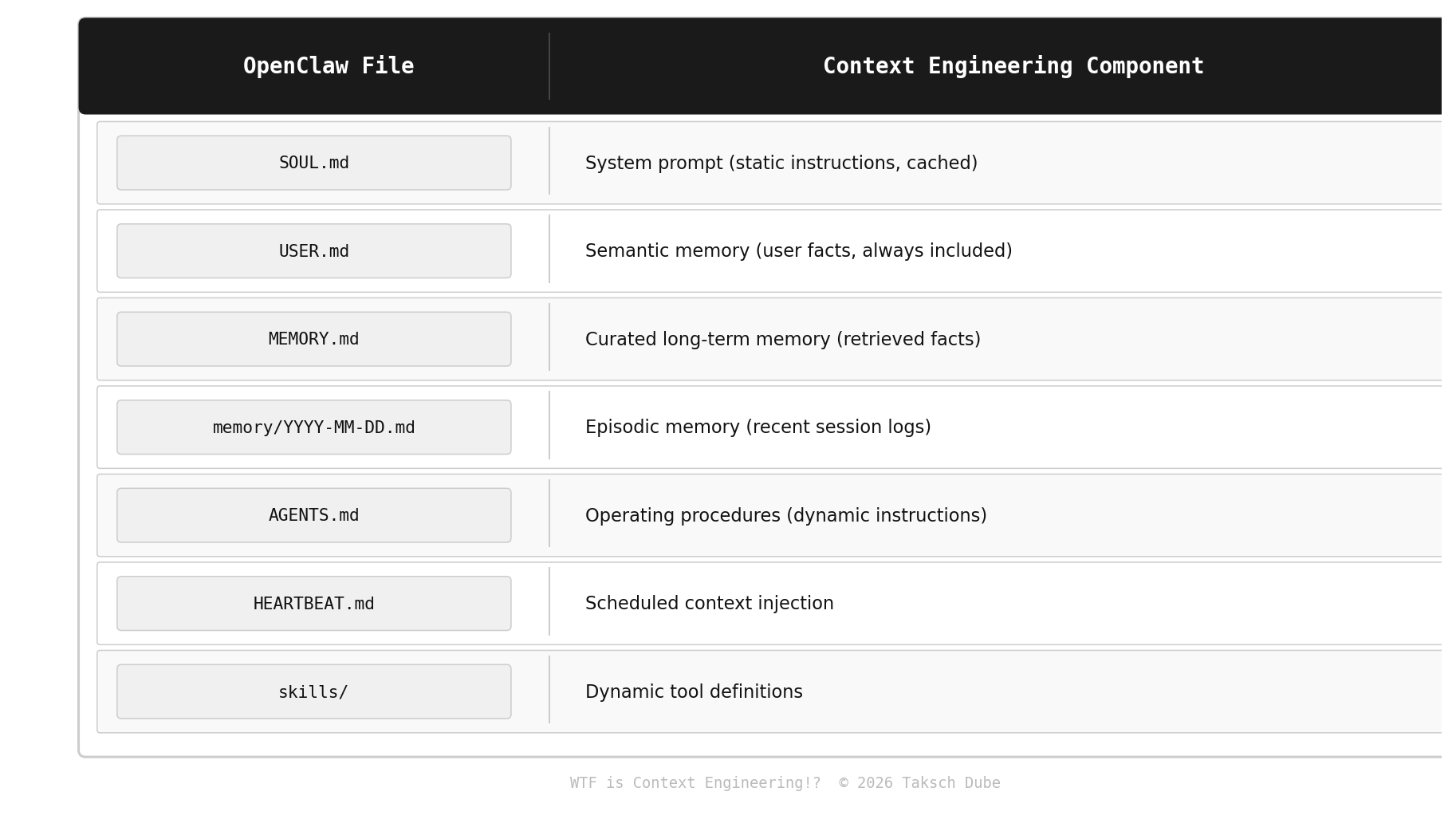
At session start, OpenClaw assembles all of this into a context window. The ordering, the curation of MEMORY.md, the decision of which skills to load — all of it is context engineering, just done by file system operations instead of code.
The security implications we flagged in the OpenClaw post? Many of them are context engineering failures: prompt injection via malicious skills (untrusted content in the tool definitions slot), SOUL.md tampering (system prompt corruption), memory poisoning (semantic memory injection).
The security layer my colleague and I are building addresses this directly. Context provenance — knowing where every token in your context came from and whether it’s trusted — is the missing piece.
More on that soon.
The TL;DR
Context engineering is the discipline of designing everything that goes into an LLM’s context window — not just the prompt, but the memory, retrieved docs, tool results, conversation history, and how they’re assembled and ordered at runtime.
Why it matters:
Context = tokens = money. A bloated context at scale costs thousands of dollars per day
More context ≠ better answers. The lost-in-the-middle problem is real and well-documented
Production AI systems are information architecture problems, not prompting problems
The five components to manage:
System prompt — keep it lean, cache it aggressively
Memory — build a hierarchy (working → episodic → semantic → long-term store)
Retrieved documents — rerank, structure with metadata, cap at 5 chunks
Tool definitions/results — load dynamically, summarize results, prune old ones
Conversation history — rolling compression, not full history
The ordering that works: best source at top, current message at bottom, bulk in the middle
The benchmarks:
Prompt caching: 90% off cached tokens (immediate ROI, zero effort)
Reranking before RAG: 5-15% faithfulness improvement
Memory hierarchy vs full history dump: 60-75% token reduction
Rolling conversation compression: 70% token reduction, negligible quality loss
The real talk: infinite context windows don’t solve this. Automatic optimization tools don’t solve this. You have to design the architecture.
Prompt engineering taught you what to say. Context engineering teaches you what to show.
Next week: WTF is Agentic Engineering? (Or: Andrej Karpathy just buried “vibe coding” and replaced it with something more dangerous)
"Vibe coding" was fun when you were building weekend projects. But in 2026, 95% of Y Combinator codebases are AI-generated and a paper literally titled "Vibe Coding Kills Open Source" just dropped from a consortium of universities. The vibes are not immaculate. The industry is quietly pivoting from "AI writes your code" to "AI runs your engineering org" — and the gap between those two things is where careers, security, and open source go to die. We'll cover what agentic engineering actually means, why Karpathy's reframe matters, what the research says about AI-generated code quality, and whether your job is actually going away in 6-12 months (spoiler: Dario Amodei said something spicy about this).
See you next Wednesday 🤞